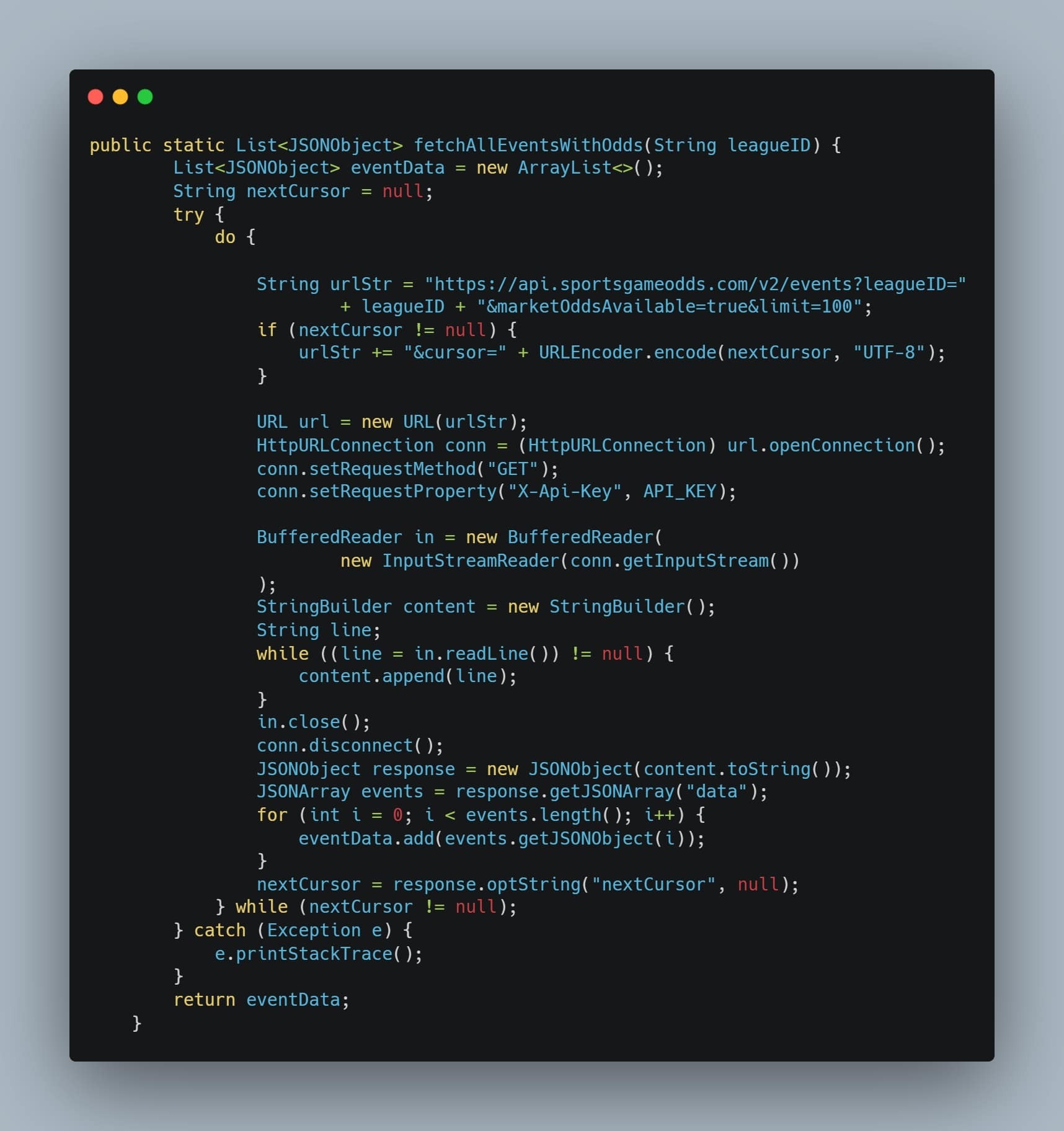
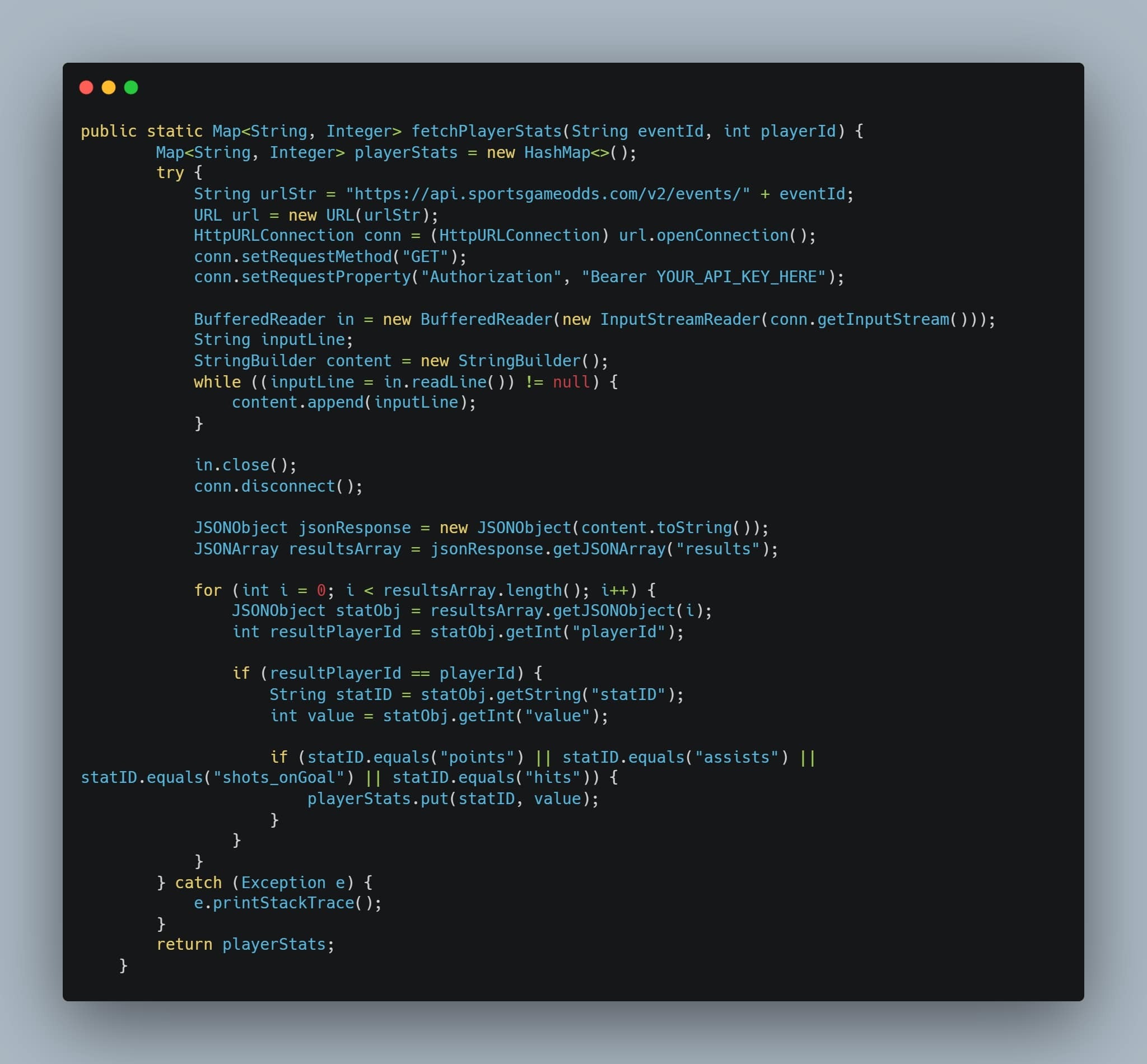
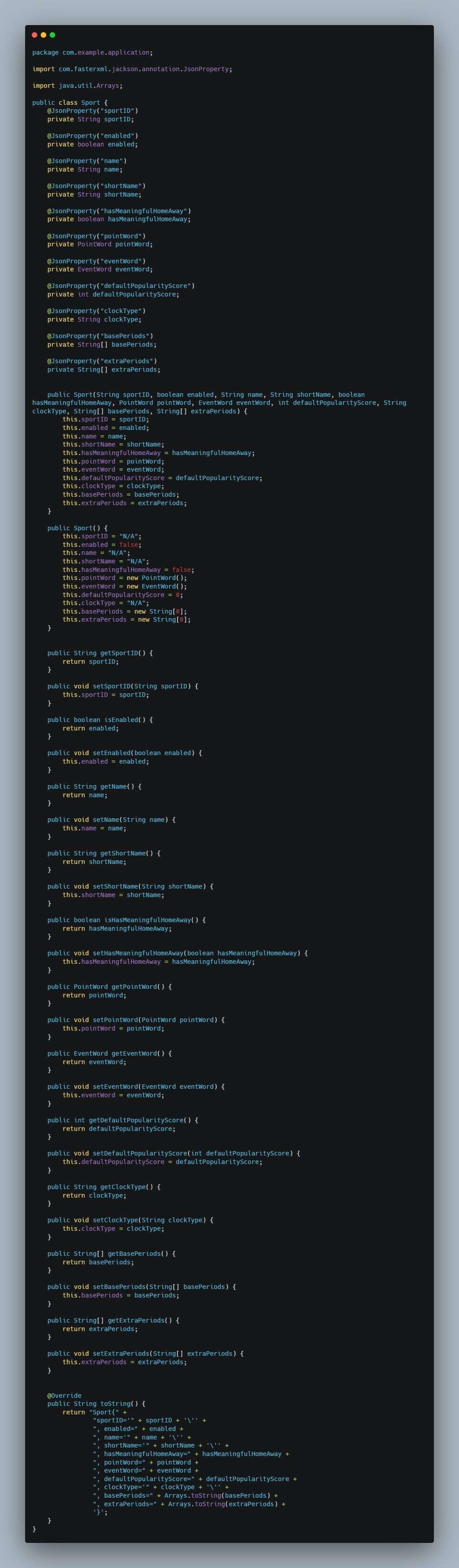
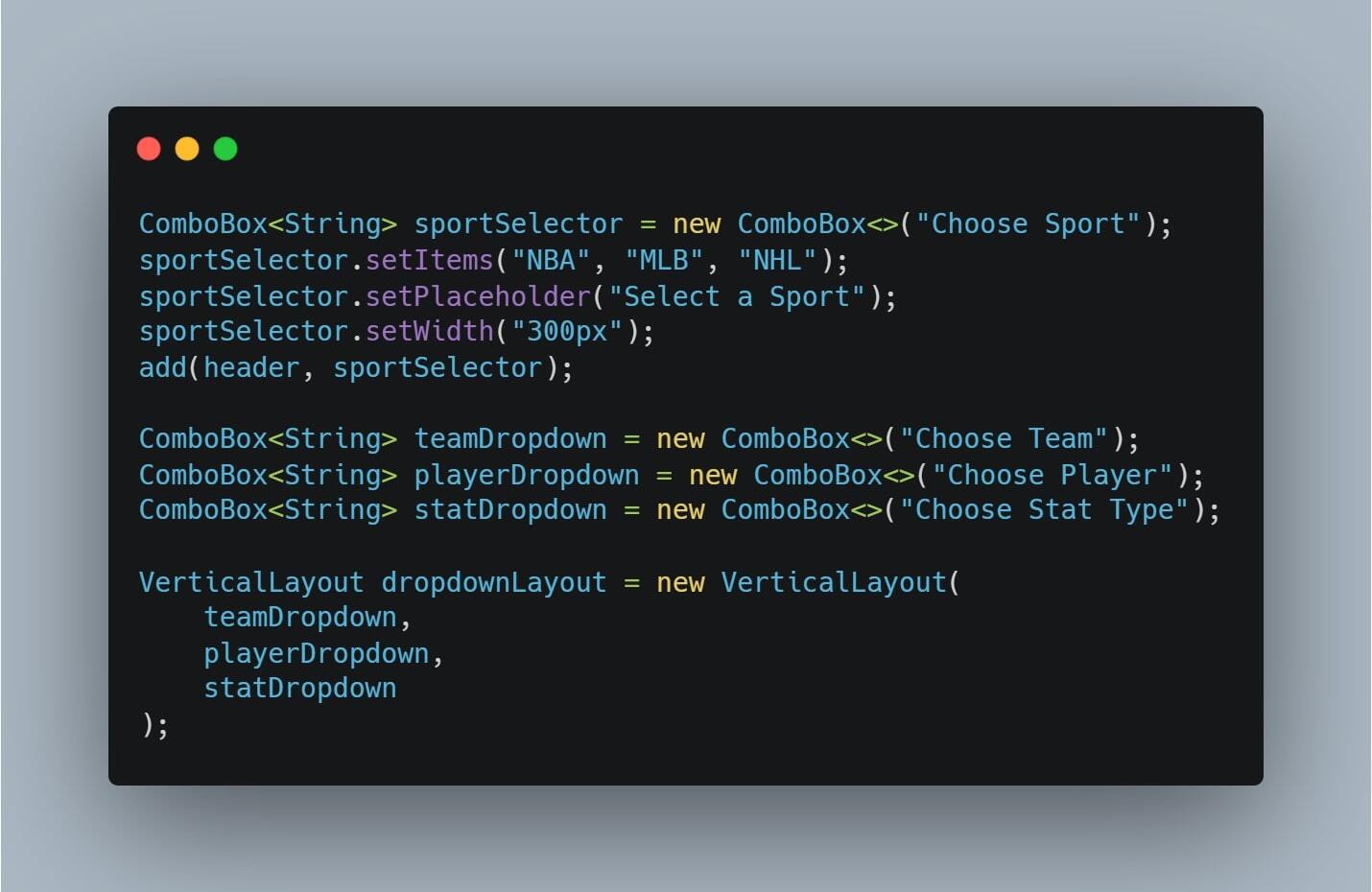
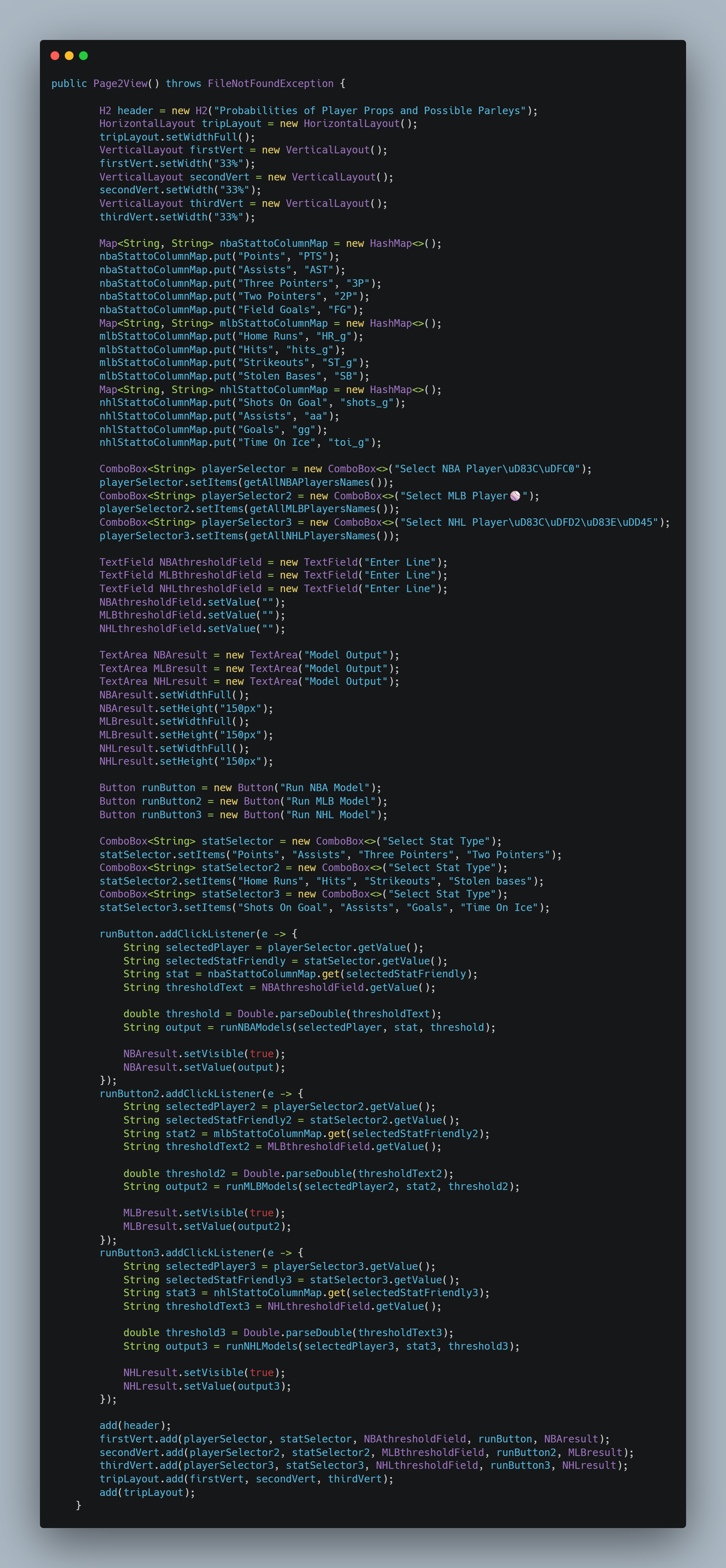
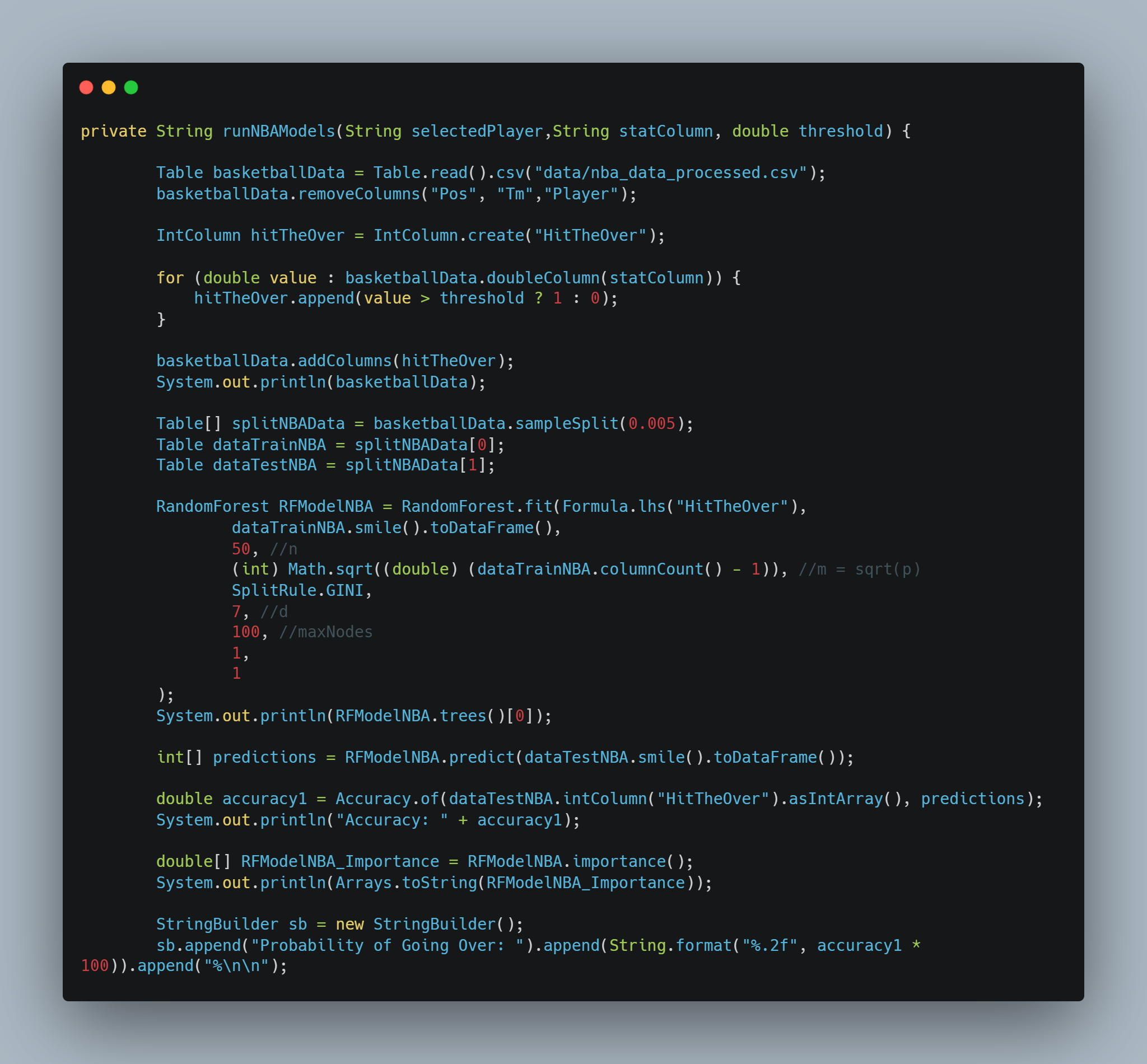
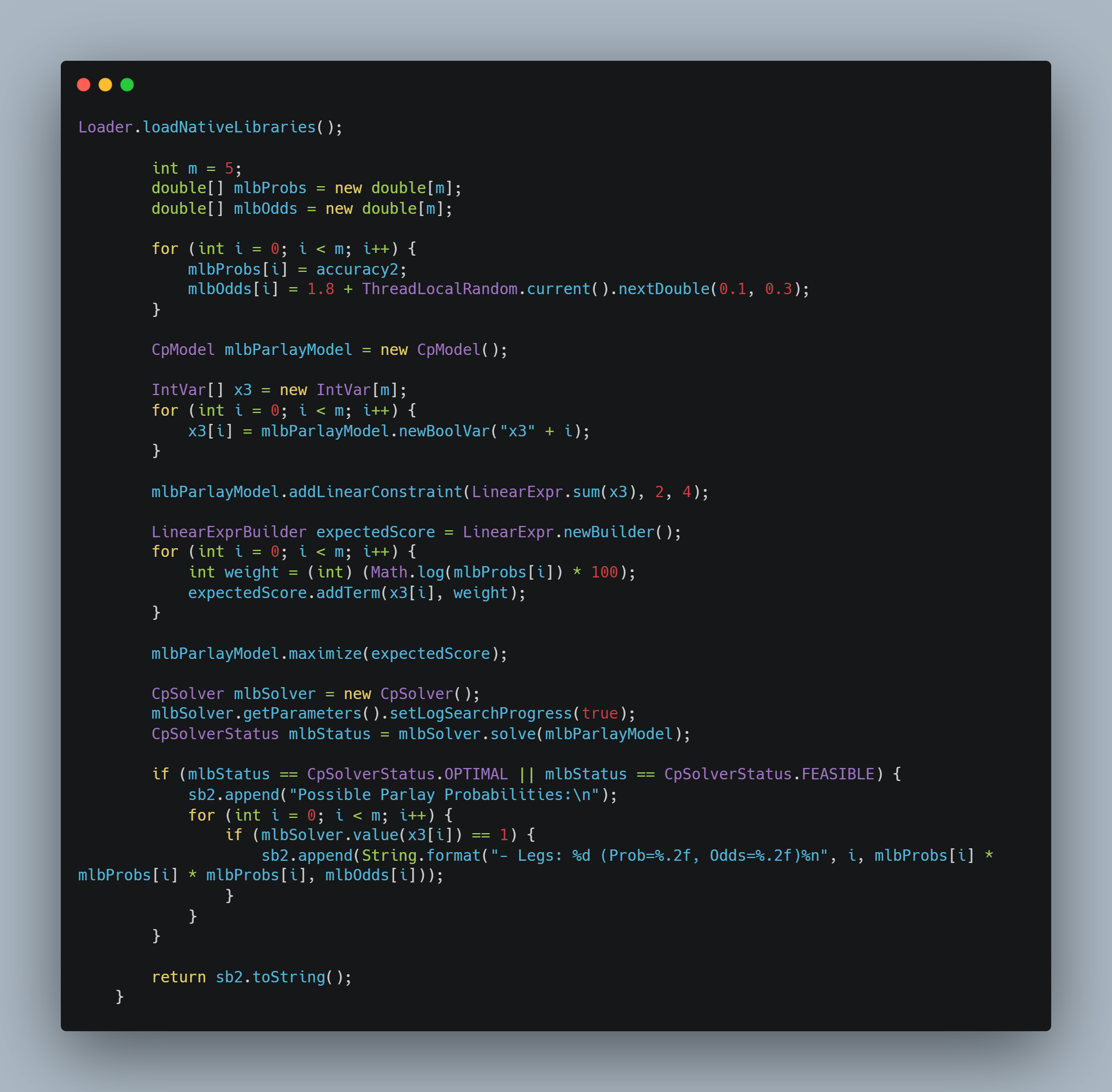
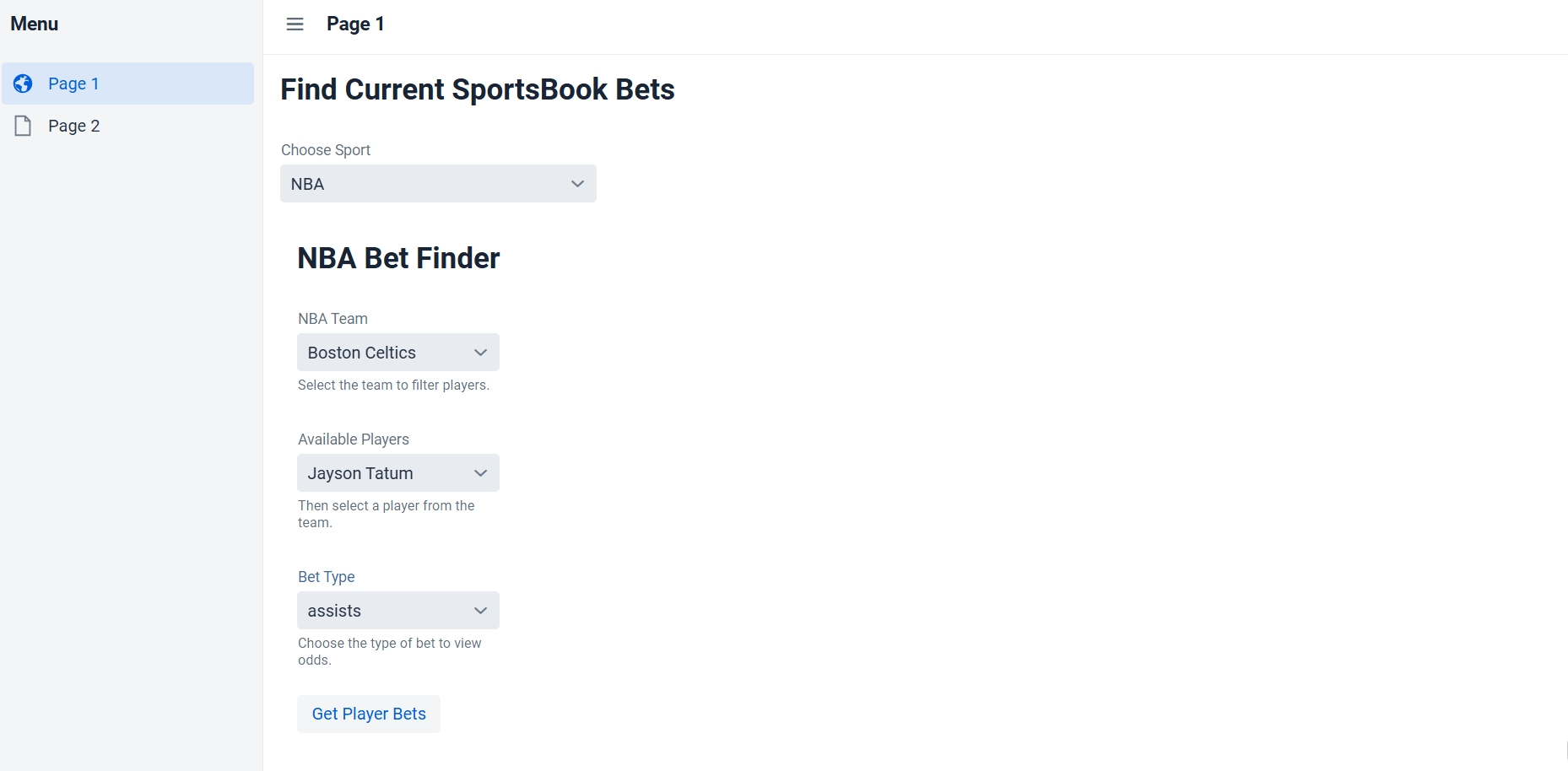
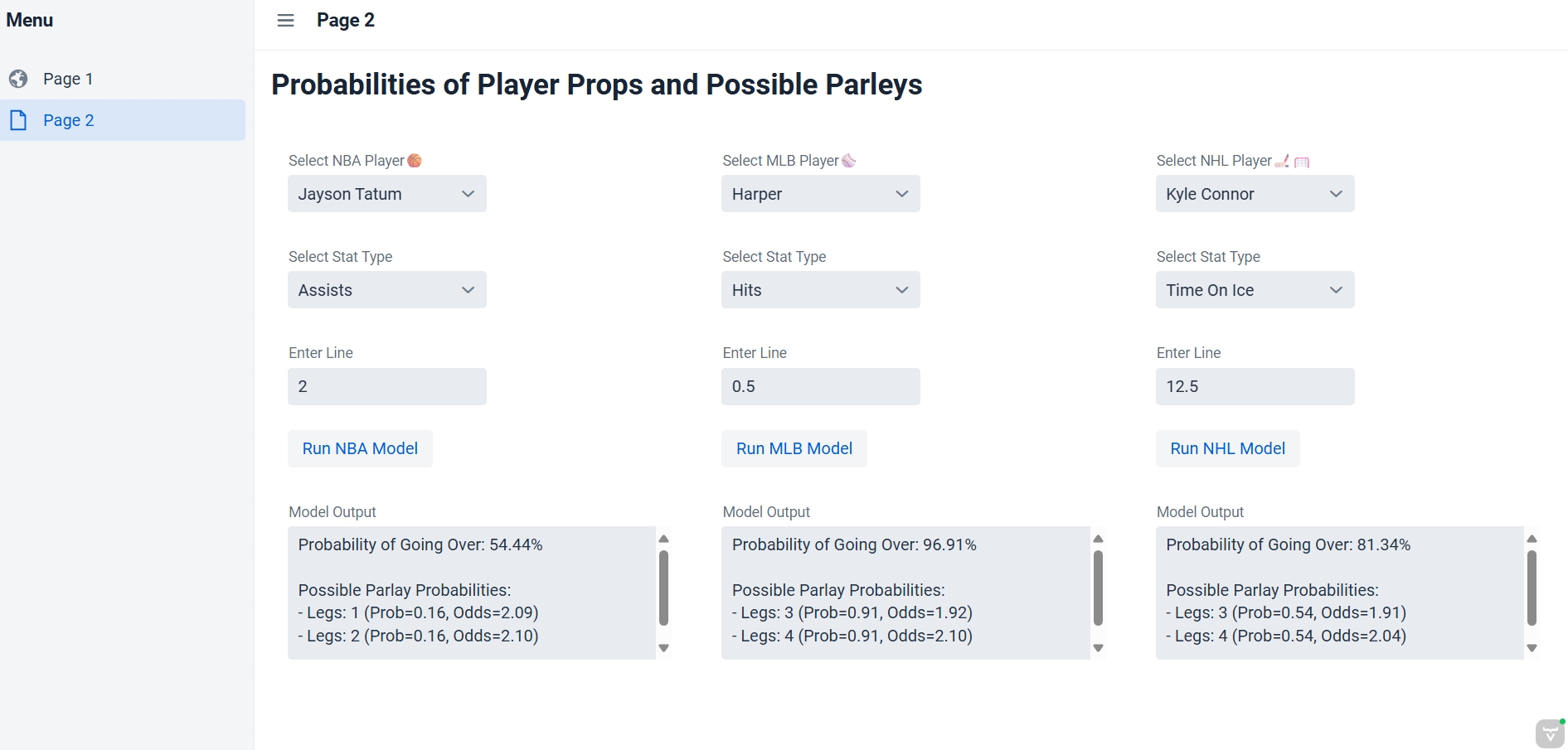
This entry showcases our completed Computing II project, which integrates live API data, Java-based back-end processing, and predictive analytics to deliver sports betting insights. The core concept centers around enabling users to select a sport and player of interest, view available betting lines, and utilize our predictive model to estimate the probability of a specific bet outcome.
Our UI is developed using the Vaadin framework, while live sports data is retrieved via the Sports Game Odds API. Predictive modeling is performed with the SMILE machine learning library to generate probability estimates for over/under prop bets. Additionally, parlay optimization is implemented using Google OR-Tools.
The accompanying slides include detailed descriptions of our design approach, and notable features throughout our code.